
https://blog.langchain.com/context-engineering-for-agents
최근 컨텍스트 엔니지니어링이라는 말이 화제가 되고 있습니다.
소셜네트워크에서도 많이 노출되고 있고, 컨텍스트 엔지니어링이라는 단어가 나오게 된 배경에는 에이전트가 관련되어 있기 때문입니다.
지금까지 LLM은 기본적으로 사람이 이용하는 것이었습니다. 그러나, 에이전트는 사람의 손이 기본적으로 개입하지 않고 자동으로 LLM이 계속 작동합니다. 따라서 프롬프트뿐만 아니라, 정보 자체를 어떻게 관리할지까지 생각할 필요성이 나왔습니다. 이 정보의 취급 방법을 생각하는 것이야말로 컨텍스트 엔지니어링입니다.
컨텍스트 엔지니어링의 목표는 두 가지입니다.
첫번째, LLM의 성능을 극대화하는 것입니다. 이는 프롬프트 엔지니어링으로 이어질 수 있습니다.
두번째, LLM에 필요한 충분한 정보를 제공하는 것입니다.
이번에는 컨텍스트 엔지니어링이 필요한 배경과 방법에 대해 설명합니다.
과제의식
LLM에 복잡한 지시를 했을 때, 그 지시가 LLM이 가지는 문제해결능력을 상회해 버리면, 태스크를 완료할 수 없게 되는 일이 있습니다. 이것은 주로 2개의 제약에 의해 발생합니다.
- 입력 길이 한계: LLM에는 입력 가능한 문장량에 제한이 있으므로, 그 중에서 해결할 수 없으면 더 이상 아무것도 할 수 없게 됩니다.
- 인식 한계: 여러 지시를 LLM에 맡기면 “Lost in the Middle”등의 문제등으로 해결해야 할 문제를 잃어버릴 수 있습니다.
이러한 한계는 LLM의 진화에 의해 확실히 해소해 가고 있지만, 사람이 요구하는 문제해결 능력으로부터는 아직 큰 격차가 있습니다.
컨텍스트 엔지니어링의 해결 방법
여기에서 등장하는 것이 컨텍스트 엔지니어링이라고 생각됩니다. LLM에 적절한 컨텍스트를 전달하는 것으로 LLM의 한계에 도달하지 않도록 문제를 해결해 나가자는 것입니다.
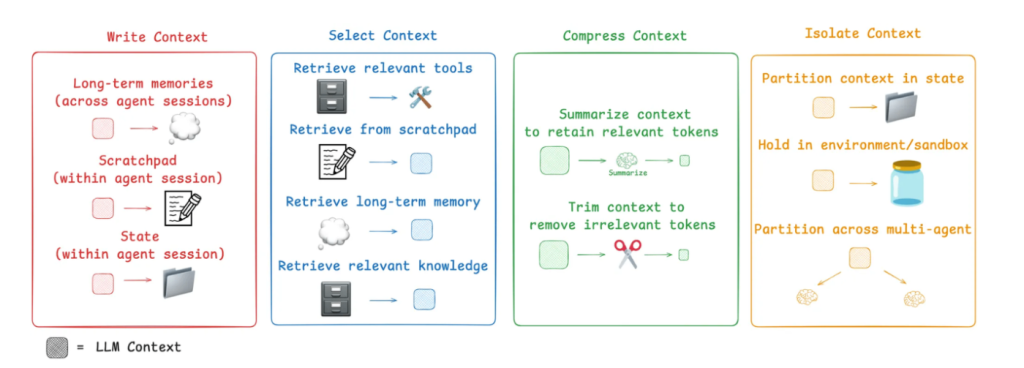
- 내보내기: 중요한 정보를 외부에 저장하고 재사용 가능하게 만들기
- 선택: 필요한 컨텍스트만 가져오고 추가 정보가 없음
- 압축: 컨텍스트를 엄선하여 밀도가 높은 정보로 만들기
- 분할: 복잡한 문제를 분해하여 독립적이고 다루기 쉬운 문제로 만들기
이러한 기술을 결합하면 LLM이 해결할 수 있는 문제를 최소화하고 문제 해결에 집중할 수 있습니다.
기법
여기에서는 구체적인 수법에 대해 소개합니다. 주의할 점은 여기서 소개하는 수법은 어디까지나 현시점에서 상정도니 해법이며, 향후에도 업데이트가 상정되는 부분입니다. LLM의 출력품질을 어떻게 올릴 수 있는지가 근간에 있다는 것을 염두에 봐주시면 좋겠습니다.
내보내기 (Write Context)
세션 내에서 얻은 정보를 외부에 저장하고 다른 세션에서 재사용할 수 있도록 하기 위한 것입니다.
- 메모 쓰기 내보내기
중요한 내용과 정책을 외부 메모 쓰기로 남겨둡니다. 예를 들어, 실행 절차를 기록해 두면, 세션을 다시 시작할 때 계속해서 다시 시작할 수 있거나 “Lost in the Middle”로 정보가 사라지지 않습니다.
- 기억 내보내기
세션 내의 정보 중, 다른 지시에 관련되는 것 같은 정보는 기억(Memory)으로서 장기적으로 이용할 수 있도록 합니다. 이렇게 하면 예를 들어, 매번하고 있는 지시나 빠지기 쉬운 실패를 반복하지 않고 끝나게 됩니다.
실천팁
정보량이 너무 많으면 그것만으로 컨텍스트를 압박하거나 선택의 비용이 발생해 버리기 때문에, 너무 내보내는 것은 주의가 필요합니다. 대책으로서는 다음과 같은 것이 생각되지만, 운용 방법에 의해 조정해 보세요.
- 출력 내용을 지정하여 정보가 산만해지지 않도록 합니다.
- RAG와 결합하여 효율적인 검색과 결합합니다.
- 단순히 데이터 양을 제한하여 오래된 데이터를 폐기합니다.
선택(Select Context)
- 메모 쓰기, 기억 불러오기
새로운 세션의 시작시나 문제의 전환 시 등에 읽어들일 수 있도록 하는 것으로 LLM이 다음에 해야 할 일을 파악할 수 있게 됩니다. Tool로서 또는 규칙기반으로 건네주는 등을 상정할 수 있습니다.
- Tool 선택
LLM은 기본적으로는 텍스트, 이미지의 출력 이상의 일은 할 수 없고, 또한 산술등의 지시를 서투르기 때문에, 그러한 처리를 적절히 외부의 기능에 의지해 가야 합니다. 또한, 지시의 목적 그 자체가 되는 일도 있으므로, Tool을 늘리는 것이 즉 LLM에 할 수 있는 것을 늘리는 수단이 되고 있습니다.
- 정보 검색
LLM의 내부지식에는 한계가 있습니다. 이 경우에 유효한 것이 RAG 또는 웹검색입니다. 특히 기업 내의 기밀 정보 등을 다룰 때는 RAG를 이용하여 중요한 정보만을 적절히 LLM에 전달할 필요가 있습니다.
실천팁
Tool 선택은 실제로 생각하고 있는 것보다 정밀도가 나기 어려운 부분입니다. 실제로 이용해 보면, 어느 정도 문제 없게 선택할 수 있게 되는 것은 o3, Gemini 2.5~, Claude 3.7-Sonnect~와 비교적 최신 및 최고 성능의 것으로 좁혀져 옵니다.
이 문제에 대한 대책에는 다음과 같은 것이 생각됩니다.
- 실행할 도구를 한정해 버려 선택시키지 않음
- 고성능 LLM 사용
- RAG와 함께 자연어로 선택할 수 있도록 함
압축
- 컨텍스트 압축 및 잘림
불필요한 정보를 없애는 것으로 LLM의 컨텍스트 윈도우의 한계를 넘지 않도록 하고 추론의 성능을 끌어올릴 것이 가능합니다.
실천팁
압축은 실제로 가능하면 피하고 싶은 방법입니다. 물론 필요한 정보를 제대로 남길 수 있으면 좋은 방법이지만, 얻어 필요한 정보가 빠집니다. 오히려 중요한 것은 LLM에 풀 수 있는 태스크를 압축이 필요없이 풀수 있을 정도로 세세하게 하는 것으로 압축은 최종 수단이라고 생각하는 것이 좋습니다.
분할
- 처리 분할, 분기
LLM을 해결하기 위해 문제를 분할하여 각 세션에서 해결해야 할 문제를 줄이는 방법입니다. 특히, 여러 에이전트가 여러 에이전트가 분담하여 문제를 해결하는 방법과 같은 세션 내에서도 짧은 목표를 설정하여 문제를 해결하는 방법이 있습니다.
실천팁
지금까지의 주장과 모순을 한 이야기에 들릴지도 모르지만, 가능하면 처리는 분할하지 않는 편이 좋습니다. 이유는 분할하는 과정 그 자체로 실수가 발생할 가능성이 있기 때문입니다. LLM에 지시하는 경우는 다음과 같은 순서로 생각해 가고, 가능하면 위쪽의 방법으로 해결하는 것이 바람직합니다.
- LLM이 분할없이도 해결할 수 있을 정도로 짧고 명확한 지시
- 세부 목표 설정만으로 단일 세션으로 해결할 수 있는 지침을 냄
- 동일한 에이전트가 독립 세션을 반복하여 해결할 수 있는 지시
- 여러 전문 에이전트가 각각 문제를 해결함으로써 실현할 수 있는 지시
정리
컨텍스트 엔지니어링의 사고방식과 그 안에서 등장하는 구체적인 기법에 대해 소개했습니다. 중요한 것은 LLM이 최상의 성능을 발휘할 수 있는 환경을 만드는 방법입니다. 그리고 이를 실현하는데 있어서 중요한 요소가 작은 지시, 해결에 필요한 충분한 정보, 실행 가능한 수단의 제공입니다.
이 아이디어는 에이전트에 국한되지 않으며 LLM을 활용하는 모든 시스템에 적용할 수 있습니다. 여러분의 해결하고 싶은 과제는 다양하다고는 생각되지만, 여기서 소개한 사고방식이나 수법이 해결의 실마리가 되면 다행입니다.
©2024-2025 GAEBAL AI, Hand-crafted & made with Damon Jaewoo Kim.